
The last couple of decades have seen the rise of e-commerce throughout the world, and both merchants and customers are now able to experience a level of comfort in dealing and shopping that could only be imagined before. For the merchant, this means easier showcasing of goods, 24×7 operation, a chance to expand their global outreach and so much more. Unfortunately, it isn’t just the stores that have evolved, major problems that shop owners used to face in the pre-internet era such as fraud have evolved too.
Fraud is a much less talked about facet of e-commerce which has a large impact on the revenue of a business. E-commerce businesses across different industries have seen up to 40% of fraudulent orders on a regular basis.
Types of fraud
E-commerce frauds happen on Cash On Delivery (COD) as well as prepaid orders. One common type of fraud is the Return To Origin (RTO) fraud where the customer initiates a return on receiving the product and either using it temporarily, swapping it with a faulty/damaged product or denying that they ever received the product. Payment frauds related to credit cards, where the customer initiates a chargeback on receiving the product and denies having made a purchase with the card in question, are also quite common. Other types of e-commerce fraud include promo code abuse, where a single customer signs up multiple times on an app to avail discounts using promo codes, and account takeover, where a fraudster gains access to a customer’s account and purchases multiple items on the customer’s behalf.
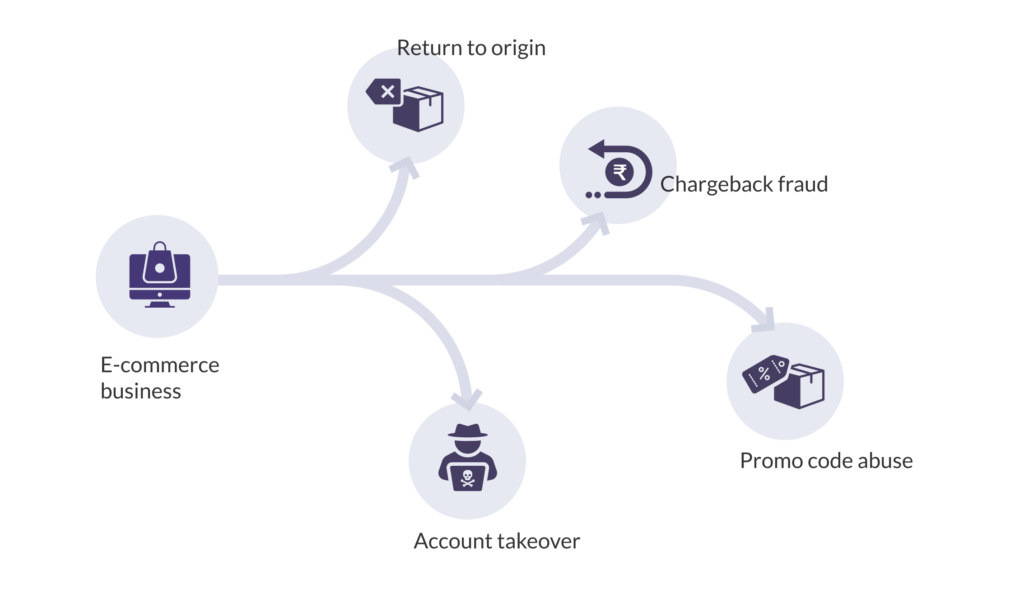
However, it would be a gross underestimation to think that e-commerce frauds are limited to these types. Frauds are ever-evolving and new ways of defrauding come up more often than one would imagine.
Related Read: Fraud Analytics: A Guide to Preventing Financial Fraud
The data age
Traditionally, tech solutions to problems centred around fixed rules for solving problems. For example, to tackle e-commerce fraud, one of the rules we can create is, “if the mobile number and pin code of the customer doesn’t seem correct, declare the order as a fraud”, which roughly translates to (note that this is just an example and more rigorous checks can be carried out),
if (no. of digits in mobile number != 10) then
if (length of pincode != 6 or no. of digits in pincode != 6) then
reject order;
This seems like a good way to tackle this problem, but this has several issues, the most important one being that we don’t really know what rules to build and apply. While active research is being carried out to solve such problems, something like e-commerce fraud is ever-evolving and hence, no fixed set of rules will ever be able to cover all fraud cases.
This is where data-based solutions come in. These involve recording and analyzing data over a period of time and trying to figure out patterns in the data that would provide enough insight to come up with a solution.
Large companies record mind-boggling quantities of data every day, given that we as end-users turn to the internet for much of our daily activities. As early as 2017, for instance, in every minute of an average day, Google conducted 3.6 million searches, Skype users made about 1,54,200 calls, Netflix users streamed 69,444 hours of videos and Instagram users posted 46,740 photos. By 2018, over 2.5 quintillion bytes of data was generated each day of the year. As of 2020, it’s estimated that about 1.7 MB of data is generated by every single person on Earth every second, and all of it is being stored. The age of data is upon us.
Implementing rule-based solutions for complex and ever-changing problems such as e-commerce fraud is not feasible and hence data-based solutions are preferred for such problems.
Hence, it is no surprise that data-based solutions have become the most popular ways of tackling the e-commerce fraud problem. Specifically Machine Learning, a concept closely related to Artificial Intelligence (AI) is employed these days to try and solve this problem.
The basics of Machine Learning
How does ML work
Machine Learning (ML) is a set of algorithms that can actively recognize patterns from large amounts of data and use these patterns to predict a certain parameter – in this case, whether a given order is fraudulent or not. Machine Learning has been around for a while now – since the later part of the 20th century but only came into mainstream programming in the 2010s.
On a broad level, ML algorithms can be classified into supervised and unsupervised algorithms. Both kinds of algorithms require many examples (data records) to learn any useful patterns. The difference is, supervised ML algorithms require labels for each data sample while unsupervised ones don’t. A popular example of a supervised ML problem can be rent prediction; we can provide a dataset containing various attributes pertaining to the area, location, number of rooms, size of rooms, etc. of the house and label each house with its corresponding rent.
A supervised ML algorithm can learn how these attributes affect the rent of the house. An example of an unsupervised algorithm can be learning from user behaviour and giving recommendations based on their liking. Detecting e-commerce frauds is mostly a supervised classification problem, given that a dataset with orders and labels (fraud/not fraud) would be available.
To sum it all up,
Supervised Machine Learning algorithms require labelled samples to learn from data, while Unsupervised ML algorithms don’t need labels to learn from data.
Further, this problem is a classification problem, in which the output can be one of a predefined set of values called classes (‘fraud’ and ‘not fraud’ in this case), as opposed to a regression problem, where the output can be a range of real numbers (say ‘10.0’ to ‘100.0’). A classification problem in which the number of output classes is equal to 2, as in this case, is called a binary classification problem, as opposed to a multi-class classification problem, where the number of output classes is more than 2.
The working of ML models varies according to what algorithm is used to implement the model, however, all supervised models follow a certain pattern of working. The very basic idea of a model is that it would learn a function mapping between the inputs ‘X_i’ and the output ‘Y’ using the examples given to it. The complexity of the function that a model can learn varies according to the algorithm. For instance, an algorithm like Logistic Regression would end up learning a much simpler mapping as compared to a Multi-Layer Perceptron. This function is called the Hypothesis. A sample hypothesis for a model operating with two features ‘X_1’ and ‘X_2’ can be:
h(X) = W_0 + W_1*X_1 + W_2*X_2
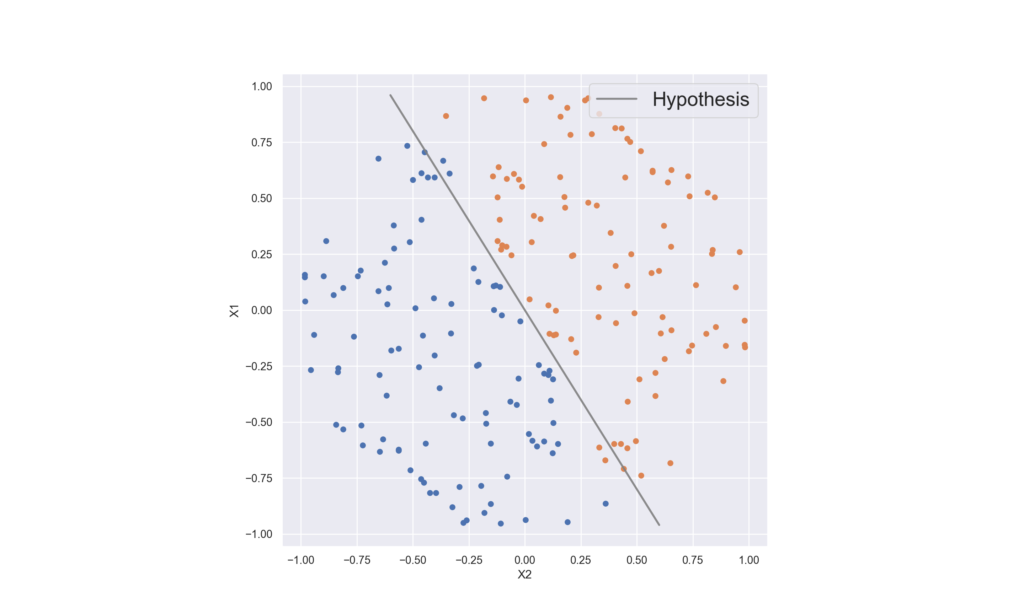
This is a fairly simple hypothesis that is used by a model like Linear Regression. The figure below demonstrates how a simple hypothesis function like a line can do well in a binary classification task if the points from the two classes are already separate. The blue and orange points represent two separate classes. Points on the left side of the hypothesis would be marked as ‘blue’ and those on the right as ‘orange’. This would mean that most of the points could be classified correctly using this kind of a hypothesis.
In case the data is more complex, i.e. the points from both classes are more “mixed” with each other, a more complex hypothesis function will be needed.
At the core of the algorithm is a loss function, which tells the model if it is learning correctly or not. The objective of the training process is to minimize the loss function as much as possible. For each sample that the model sees, it provides an estimation of what the value of y can be for that sample. If the estimation is close to the real value, the loss function is minimized, else it increases, thereby ‘penalizing’ the model. For each update in the loss function, the parameters ‘W_0’, ‘W_1’ and ‘W_2’ are updated in such a way that the next estimation is closer to the real value. Hence, the model learns the mapping between the features and the labels.
Training an ML model involves iteratively updating certain parameters such that a loss function is minimized. The set of parameters which gives the minimum value for the loss function are used to predict the target variable for new samples.
The general process of building and using a Machine Learning model is simple enough to understand. We gather data (in this case, a dataset of recent orders) with multiple features (in this case, for instance, order date, order time, price of the product, information about the product, user account details, etc.) and label each of these as true if they are fraudulent and false if they are not. An ML model is then iteratively trained on this data and tested on a hold-out set (also called the test set), which is never shown to the model during training (more on this later). If the model performs well on the test set, we decide to use the model to predict the order status of future orders.
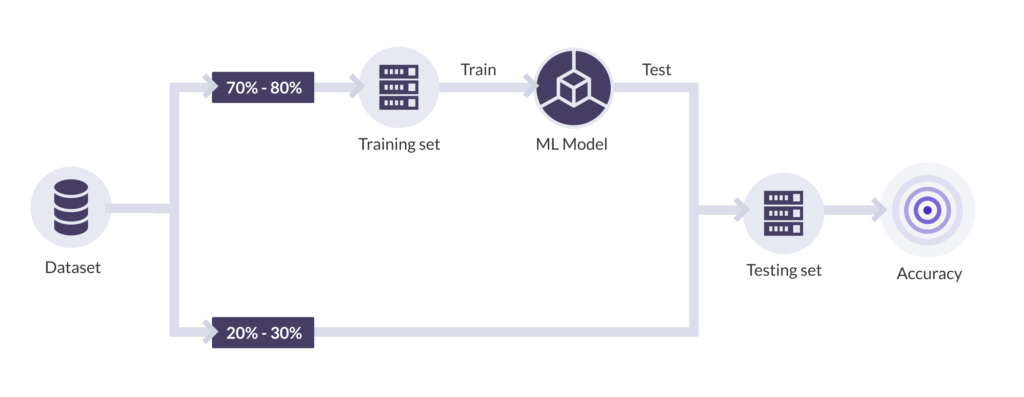
Now, once a new order is passed to the model, it can predict if the label for this new order would be true or false. This being said, the model would not output a value saying ‘true’ or ‘false’ exactly, it would output the probability of the order being fraudulent, i.e., ‘P(fraud)’. It would now be up to us to set a cutoff on the probability that would work for us. This is explained in more detail in the next blog.
Why use ML for this problem
In a nutshell, the reason why ML-based solutions for e-commerce fraud detection are gaining popularity fast is that we as humans cannot fathom how each factor in the e-commerce ecosystem might be affecting the fraudulence of a particular order. We know that there are a lot of factors that might hint at an order being fraudulent, for instance, a user might have made an abnormally large amount of orders in the past few minutes, or the user has entered a monkey-typed address in the address fields or the user has skipped over the basic information needed for an order to be delivered, which will result in an RTO. We cannot, however, evaluate each factor and determine their contribution towards the fraudulence of that order manually.
To prove this point, consider that we take a traditional approach towards solving this problem. We would eventually come up with a set of rules that will determine if an order is fraudulent or not. For example,
if (X_1) then if (X_2 and X_4) then …
The rule is far more complex than we as humans can write in an affordable amount of time. On the other hand, Machine Learning models can come up with such rules in a very short amount of time and hence reduce cost, time and manual labour on this task.
Another reason is that these rules can be dynamic and can change over time. Fraudulent users keep changing their tactics to avoid getting caught and novel ways of committing fraud keep coming up from time to time. Giving valuable resources into creating rules only to change them over time is a very cumbersome and wasteful task, and ML provides a far more comfortable solution.
There’s more to come!
This is only the first of the four-part blog series on how Machine Learning can be used to effectively detect fraud in e-commerce. The next instalment of this series would focus more on the technical aspects of which algorithm to choose for this Machine Learning task and which features can be created for the task of detecting e-commerce frauds. Stay tuned for more!


